
Not your lame LangChain Introduction
This article covers the theoretical aspect of LangChain by building fundamental blocks of the challenges that a developer can face when creating something as simple as a chat application, notably using custom data. It also explains how Langchain comes into the picture to integrate, automate, and produce a complex chat application employing seamless integration with multiple LLMs such as OpenAPI, Gemini, Huggingface, and many more.
1. World before LangChain
Before starting with LangChain and its technical aspects, we should first know what problem it is trying to solve. Imagine you have a huge compilation of books and would like to create a chat application that knows the literature you provided. You could ask any question or summarise it using that chat app.
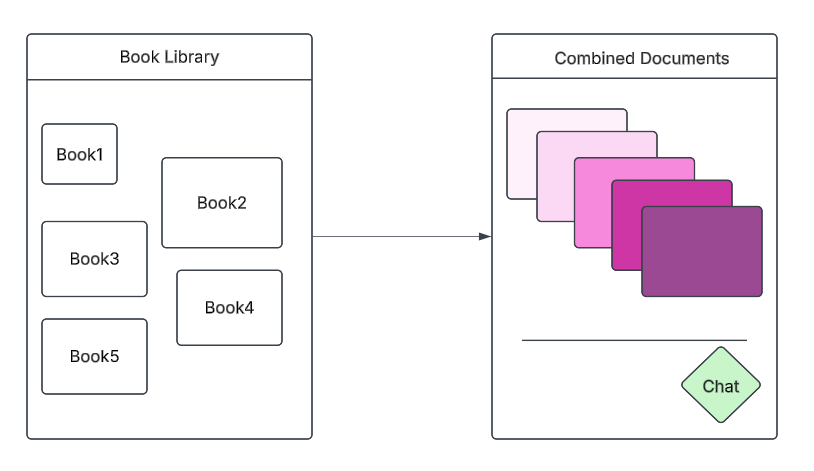
This high-level image tells us that we have built an application that is a combination of books through which users can ask any question.
Some of the possible questions you could ask:
- Explain page number 5 like I am five.
- Generate True or False questions for my exam
- Generate small notes which I can use to cheat in my exam
Ah, you get the idea. So let’s discuss the design of this application without using LangChain.
2. Building a Chat Application Without LangChain: The Hard Way
Let’s discuss the application. But before that, we need to implement a system design for such a simple yet complex application.
2.1. High-Level Architecture Overview
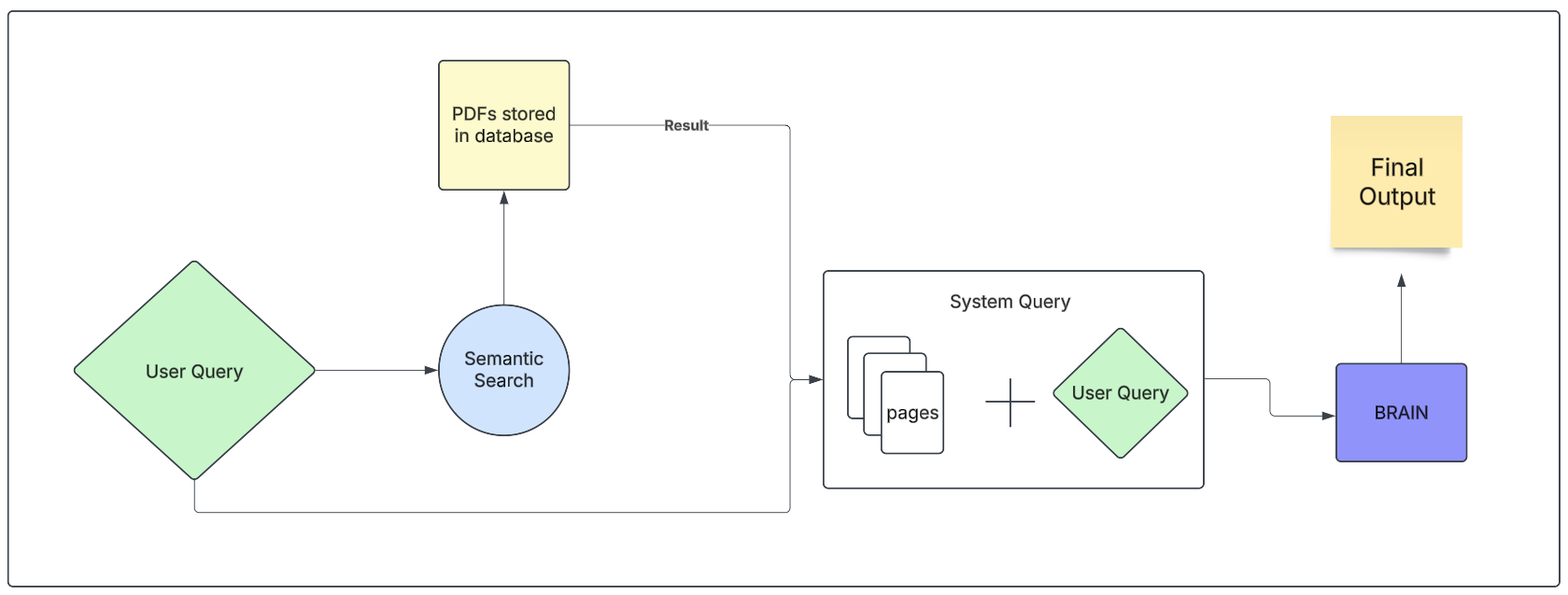
Suppose as a user you ask a question from your system “What are the assumptions for Linear Regression”, now based on the text corpus you have provided, stored in a database, this design will take that query and perform a “semantic search” and will return the relevant pages (in this case the pages containing the information regarding the question we asked) and create a "system query". This will then be transferred to the BRAIN (which is not yet disclosed as to how it works and what it is, we discuss this later). Here our BRAIN is crafted in such a way that it has the capability of Natural Language Understanding such that it understands our query. Secondly, it should have context-aware text generation ability to create the answer. Finally, our BRAIN returns the answer to the original question we asked.
This design further raises questions, what is semantic search? How BRAIN can generate answers? And more importantly, why are we using it when we can directly feed the whole document to our BRAIN component and get the answer anyway? Here it gets interesting, the document we have is a thousand pages and we doubt some topic “Linear Regression” which is present on page 462. Now, there are two ways we can approach this:
-
Approach 1: Go to our mentor hand over the book and ask that we doubt this topic.
-
Approach 2: Go to the same mentor state the page number and ask the question.
Obviously, Approach 2 is better since our mentor can directly look into the problem and clear the doubt right away. The same scenario works for our app as well. If we hand over the whole document, it will be computationally expensive and the results will be sub-par.
This is where semantic search plays a crucial role. But what exactly is it? Well, let’s discuss that by comparing another search approach and how semantic search is fruitful here.
2.2. Type of searches
There are many types of searches which can be performed some of which we are interested in are:
2.2.1. Keyword Search
Keyword search in documents helps find relevant information by matching search terms with words in the text. For example, searching “LangChain memory” in a documentation file will return sections where both words appear. However, it has drawbacks—it only works for exact matches, so “LangChain recall” might not show the same results even if the context is similar. It also fails with synonyms and doesn’t understand intent, making it less effective for complex queries. More advanced methods like semantic search address these limitations by understanding meaning, not just keywords.
2.2.2. Semantic Search
Semantic search improves keyword search by understanding the meaning and intent behind a query, rather than relying on exact word matches. Unlike keyword search, which only finds documents containing the exact terms, semantic search can retrieve relevant results even if different words are used. For example, searching “LangChain recall” would still return results about “LangChain memory”, recognising that both are related concepts. This makes it more effective for handling synonyms, natural language queries, and context-aware retrieval.
This is the reason we are using semantic search rather than keyword search.
Now that we know why we are using semantic search and what it is, it is time to look explore design of the application.
2.3. System Design
Let’s dive deep into the techincal architecture of the application and understand the complexity of creating such a beautiful and simple yet extremely complex chat application without the knowledge of LangChain.
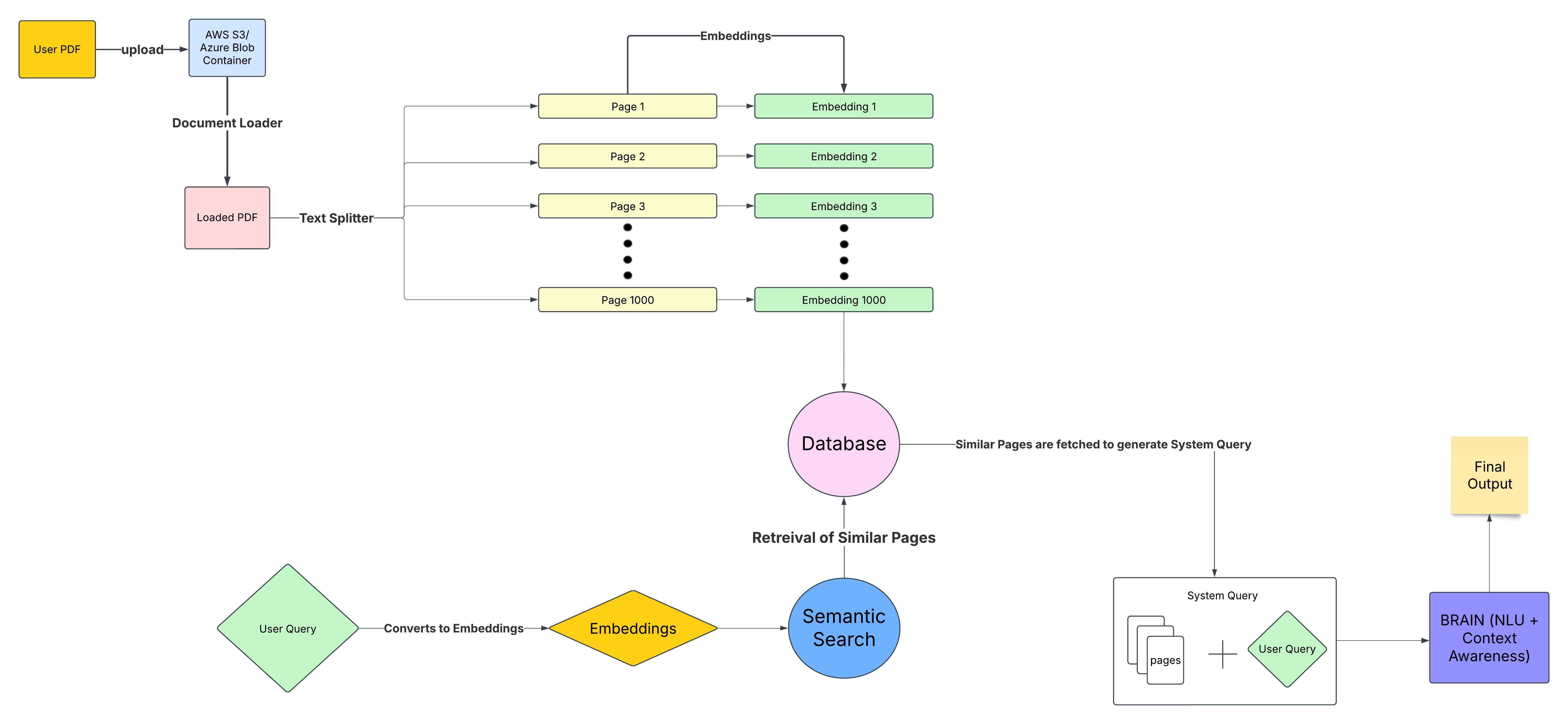
At first glance, by looking at this design, if we go in simple terms, the workflow works something like this.
The user has a corpus stored in cloud storage such as AWS or Azure Blob Storage, and this collection of PDFs is loaded using a “Document Loader” for splitting purposes. After that, the documents are split into pages using “Text Splitter” and converted into embeddings (which is just a fancy way of describing a representation vector which contains the text but in numerical form which a machine understands)1. Popular services include Amazon Bedrock2.
To give a simple example, to understand an embedding, say we have a text “I am the one who knocks.” This text will be represented into an embedding in an n-dimensional vector like this [0.02,0.55,1.455,0.44.,.....,-0.555].
By this logic, every sentence, page or word can be transformed into an embedding depending on the use case. But creating an embedding every time a user inputs a query is a bad design and computationally expensive, so what do we do? Simply, store them in a database for persistence and quick retrieval. Some of the popular choices include Pinecone or Weaviate3.
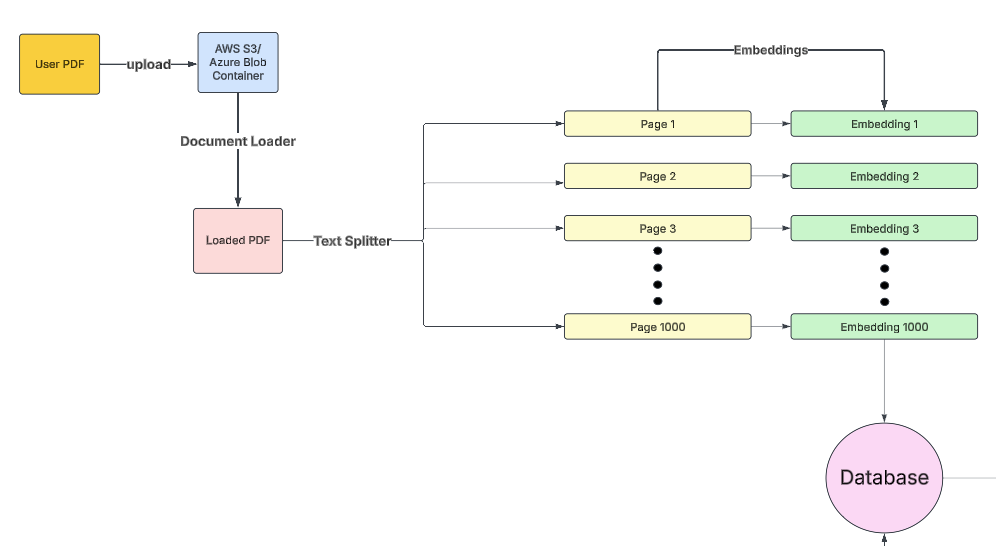
We have created our own embeddings database which we can now use to perform semantic searches. But this is all from a builder’s perspective.
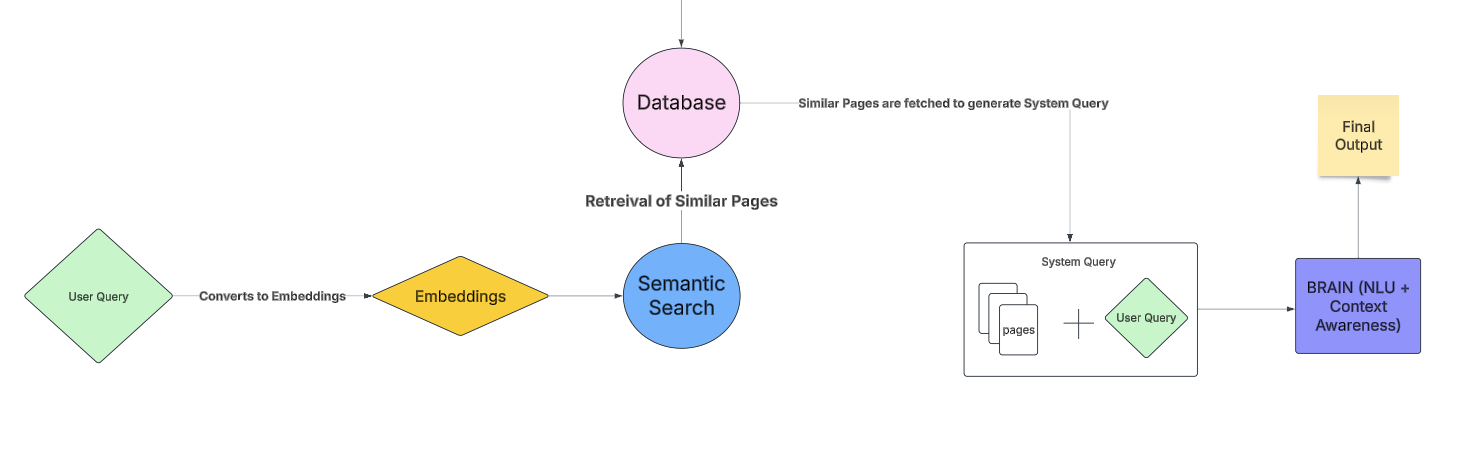
From a user point of view, all we have to do is ask our query, which will be then converted into embeddings that we looked into just now, using semantic search, the relevant documents will be fetched from the database which we created earlier and these relevant documents (containing the semantic meaning of the words, not just the word search) will be sent off to create a “System Query” (which is again a combination of the user query and the relevant pages which we just fetched) then these will be passed to the “BRAIN” which has NLU and Text generation capabilities to process and generate an answer to our query and return a response which will make the user happy!
Hoping I was able to explain the low-level system design. It Seems easy enough in today’s world, but let’s go through some of the challenges that we will face with this method:
2.3.1. Challenge 1
The number one challenge here in our app is to create our BRAIN (our first component), which is capable of generating text given the query understanding it and it can generate relevant text. And guess what this text generation got its first breakthrough from one of the most famous papers in NLP “Attention is All You Need”4. Then came BERT and GPTs and finally what we know today as LLMs. If you guessed it, you are right, drum rolls…… the BRAIN here is none other than Large Language Models (LLMs) which are quite a buzz currently.
Today we can easily solve the first component challenge using LLMs.
2.3.2 Challenge 2
Another challenge is to incorporate these LLMs, which are humungous in size and scale, for example, deep-seek r15 has 671 billion parameters which is 400GB in size, gigantic. As a user, you cannot just download these models and use them as they are computationally expensive and even the world’s most powerful personal computer cannot handle them plus it is not economical. So, what do we do? Absolutely nothing!
Why? Because this challenge is solved by companies such as OpenAI and Microsoft. They identified this problem early on, served these LLM models to their data centres and provided us with APIs to interact with.
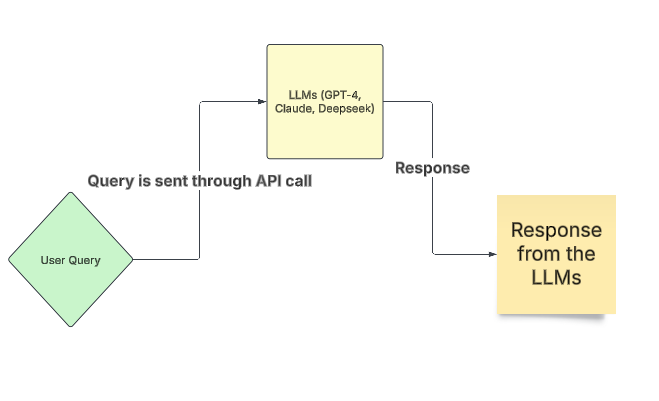
So to create the app, we use an LLM API, which gives us the advantage of only paying for what we use, which is economical and computationally inexpensive. Finally, our BRAIN here is drum rolls…..the LLM API.
2.3.3 Challenge 3
The third challenge we will face is orchestrating these components, if you look at the architecture design you might be able to point out the massive components we will have to handle including:
- Cloud Storage (AWS, Azure)
- Document Loader
- Text Splitter service
- Embedding generation using models
- Database to store embeddings
- LLMs
We have so many tasks to perform, from document loading, and embedding generation up to talking to the LLMs for which we need to create a robust pipeline to connect these components. Handling the codebase for these components will be extremely challenging, hectic and time-consuming. Even though you do manage to work through all of this, one day we might think that we do not need to use OpenAI components, rather we need to use Claude or any other LLM API for that matter. Changing this whole pipeline will cost a lot along with handling another codebase and make it compatible with other LLM APIs. Similarly, you might want to use another storage solution, or another model to create embedding.
So how to solve this challenge? You are looking at the answer.
3. The Solution? LangChain
This is where LangChain comes into play, the third challenge which is extremely complex to solve, is being solved by this famous open-source framework. It gives you the plug-and-play functionality to change just some codebase and your entire system sometimes even with just one line. To change your provider from OpenAI to Google Gemini, change your API key and change the Class and done! Similarly, you can change the entire infrastructure of your pipeline with just a little code refactoring. This gives you the power of not only focusing on your idea but also relief from not worrying about the backend. It provides a streamlined way to communicate with multiple LLMs in a magisticly complex abstraction.
3.1. Benefits
LangChain offers a range of benefits that make it a powerful framework for building applications powered by large language models. Instead of manually orchestrating multiple components like document loaders, vector databases, and LLM integrations, LangChain provides a seamless and modular approach.
Below is a summarised table outlining the key advantages of using LangChain:
| Feature | Benefit |
|---|---|
| Modular & Composable | Build reusable and flexible AI components. |
| LLM Integration | Easily switch between OpenAI, Gemini, Claude, etc. |
| Memory Management | Retain conversation history for chatbots. |
| Semantic Search & RAG | Fetch relevant data instead of sending entire docs to LLM. |
| Prompt Engineering | Optimise, manage, and version prompts. |
| Multi-LLM Support | Use different LLMs for various tasks. |
| Asynchronous Processing | Handle multiple user requests efficiently. |
| Cross-Platform Support | Works with Python and JavaScript. |
Each of these features helps developers streamline their workflow, reduce complexity, and enhance efficiency when building intelligent applications. Whether you’re developing a chatbot, a retrieval-based system, or an AI-powered assistant, LangChain makes the process more scalable and adaptable.
4. LangChain Flexibility: Switching LLMs & Embedding Models
One of LangChain’s biggest strengths is how easily you can swap components which we discussed as how code hectic they can be.
Using a simple code demonstration we can see how easily we can replace OpenAI’s GPT-4 with Google’s Gemini Pro and OpenAI’s embeddings with Hugging Face’s BAAI/bge-large-en model—all with minimal changes.
In this example we are using OpenAI to load GPT-4 model and generate embeddings and Meta FAISS to store the vectors and retrieve relevant information.
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
# Load and process documents
loader = TextLoader("data/sample.txt")
docs = loader.load()
# Convert documents into vector embeddings
vectorstore = FAISS.from_documents(docs, OpenAIEmbeddings())
# Create a retrieval-augmented QA system
qa_chain = RetrievalQA.from_chain_type(llm=OpenAI(model_name="gpt-4"), retriever=vectorstore.as_retriever())
# Ask a question
query = "What is LangChain?"
answer = qa_chain.run(query)
print(answer)
But what if you don’t want to pay OpenAI for their API, or your company decides to switch to another provider? No problem! Thanks to LangChain’s modular design, you can swap providers with just a few lines of code—as shown below, with just two small changes, LangChain allows us to swap between different LLMs and embedding models effortlessly. Let’s see it in action.
from langchain.llms import GooglePalm
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import TextLoader
# Load and process documents
loader = TextLoader("data/sample.txt")
docs = loader.load()
# Convert documents into vector embeddings
# (Changed: Using Hugging Face's BGE model)
hf_embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-en")
vectorstore = FAISS.from_documents(docs, hf_embeddings)
# Create a retrieval-augmented QA system
# (Changed: Using Google Gemini Pro instead of GPT-4)
llm = GooglePalm(model_name="gemini-pro")
qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=vectorstore.as_retriever())
# Ask a question
query = "What is LangChain?"
answer = qa_chain.run(query)
print(answer)
By changing two lines of code, we can switch models and embeddings, without worrying about the backend pipeline and other services. This showcases why LangChain is a game changer, instead of being stuck with a single LLM provider, we can seamlessly switch between OpenAI, Google, Anthropic, Hugging Face, or even local models with minimal changes!
5. LangChain alternatives
Although LangChain is extremely popular there are various other players in the market as well, Several alternatives to LangChain exist, each catering to different needs. LlamaIndex (formerly GPT Index) excels in retrieval-augmented generation (RAG) by enabling structured data retrieval. Haystack by Deepset is a strong choice for search and question-answering applications. Guidance provides fine-grained control over prompt execution, making it ideal for structured text generation. AutoGPT and BabyAGI specialise in autonomous AI agents for multi-step task automation. PromptFlow by Azure is suited for enterprises needing scalable AI workflows. CrewAI enables multiple AI agents to collaborate on complex tasks. For developers seeking flexibility, MLflow and Hugging Face Transformers allow custom LLM pipelines without predefined orchestration frameworks. The best alternative depends on specific requirements, such as retrieval, automation, or enterprise integration.
TL;DR: Key Takeaways
- Before LangChain, building AI applications required complex manual orchestration of multiple components.
- Semantic search helps retrieve only relevant text instead of feeding entire documents to an LLM.
- LangChain simplifies integration, making it plug-and-play for AI pipelines with minimal code changes.
- It supports multi-LLM compatibility, memory management, RAG, and external tool integrations.
- Alternatives like LlamaIndex & Haystack also provide solutions for specific AI use cases.
Special thanks to Nitish Singh
This article is heavily inspired by Nitish Singh’s LangChain Introduction video6 from CampusX. His ability to break down complex concepts into digestible explanations made it much easier for me to understand LangChain and its real-world applications.
The original content was in Hindi, but I wanted to cater this knowledge to a global audience so that more people irrespective of language barriers can benefit from the incredible insights he shared. By structuring this article in English, my goal was to make it accessible to a wider community of AI and machine learning enthusiasts who are eager to explore LangChain.
I sincerely thank Nitish Singh and the CampusX team for their exceptional educational content, which has helped countless learners, including myself, dive deep into LangChain and its capabilities. If you’re comfortable with Hindi and want a more in-depth, hands-on introduction to LangChain, I highly recommend checking out Nitish Singh’s CampusX video it’s a fantastic resource! 🙏 A big thank you to Nitish Sir and CampusX for their invaluable contributions to the AI community!
🚀 Exciting News: This is just the first article in a series where I’ll continue breaking down more LangChain concepts! Stay tuned for upcoming deep dives, hands-on implementations, and advanced techniques!
Thank you for reading
I truly appreciate you taking the time to read this article! 🎯 I hope it provided valuable insights into LangChain and how it simplifies working with LLMs.
If you found this helpful, connect with me on LinkedIn to discuss more LLM-powered innovations! What are your thoughts on LangChain—have you used it in a project yet?
Let’s keep exploring and building amazing AI applications together! 💡🔥